|



I'm Yu Liu, a second year Ph.D. student in Department of Automation, Tsinghua University, advised by Prof. Song-Chun Zhu. I obtained my bachelor's degree in engineering from the Department of Automation at Tsinghua University, as the monitor of the Tong Class (an AGI program founded by Prof. Song-Chun Zhu). I'm currently working at General Vision Lab in BIGAI (Beijing Institute for General Artificial Intelligence) as a research intern advised by Dr. Baoxiong Jia and Dr. Siyuan Huang. I'm also the chairman of THUAGI (Tsinghua University Artificial General Intelligence Student Association), a student society that aims to provide a platform for students, AI researchers, and industry professionals to meet new friends, exchange ideas and collaborate. Welcome to follow THUAGI's Wechat official account. If you have any cooperation intentions, feel free to add me on wechat to contact me. My research interest lies in computer vision and embodied AI, specifically 3D/4D reconstruction/generation and articulated object reconstruction/generation. My hobbies are reading, music, natural scenery and meditation.
|

|

|
|
|
|
Yu Liu, Baoxiong Jia, Ruijie Lu, Chuyue Gan, Huayu Chen, JunFeng Ni, Song-Chun Zhu, Siyuan Huang Preprint [Paper] [Project Page] [Code] |

|
Yu Liu*, Baoxiong Jia*, Ruijie Lu, JunFeng Ni, Song-Chun Zhu, Siyuan Huang ICLR 2025 [Paper] [Project Page] [Code] |
|
|
Junfeng Ni, Yu Liu, Ruijie Lu, Zirui Zhou, Song-Chun Zhu, Yixin Chen, Siyuan Huang CVPR 2025 [Paper] [Project Page] [Code] |
|
|
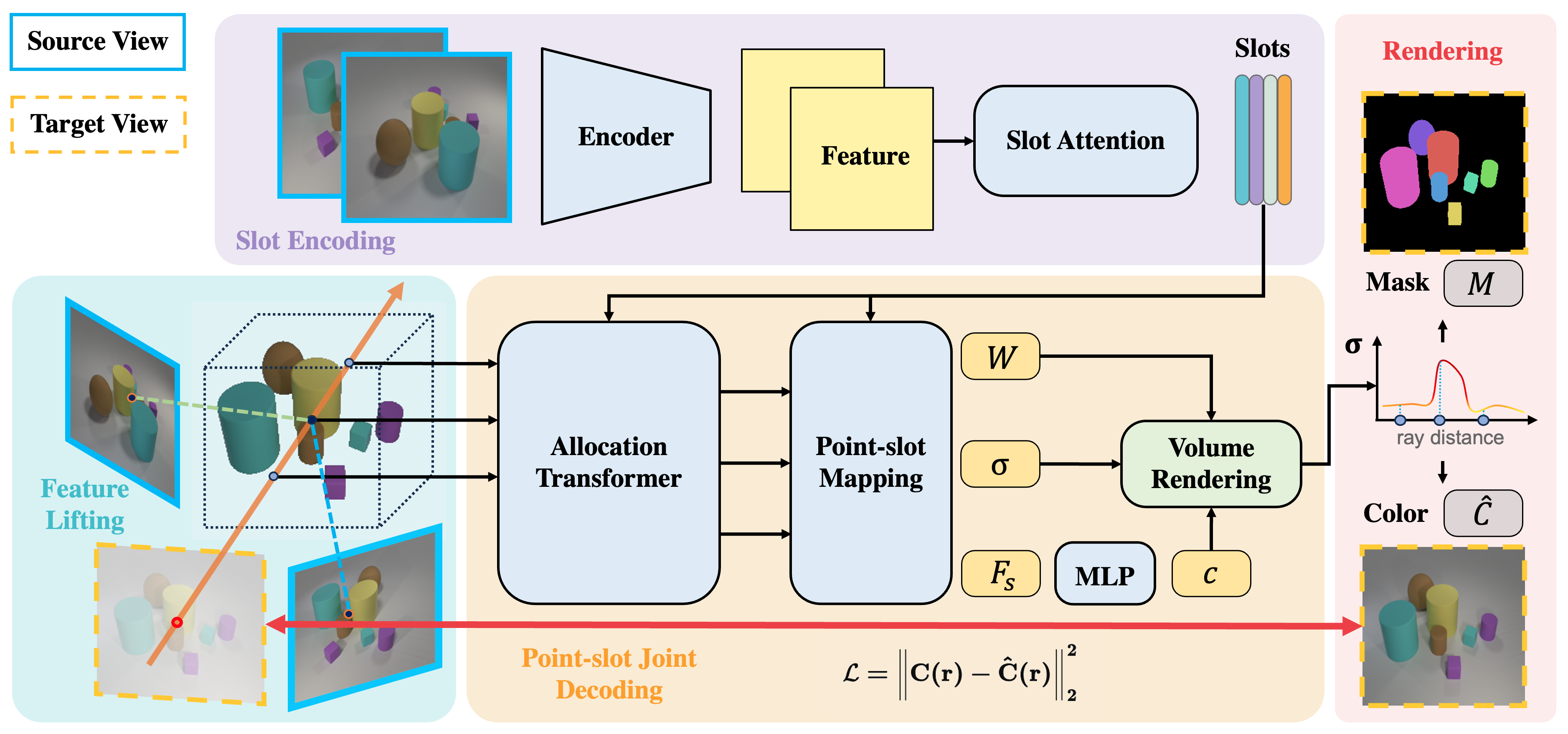
Ruijie Lu, Yixin Chen, Yu Liu, Jiaxiang Tang, Junfeng Ni, Diwen Wan, Gang Zeng, Siyuan Huang ICCV 2025 [Paper] [Code] [Data] [Project Page] |
|
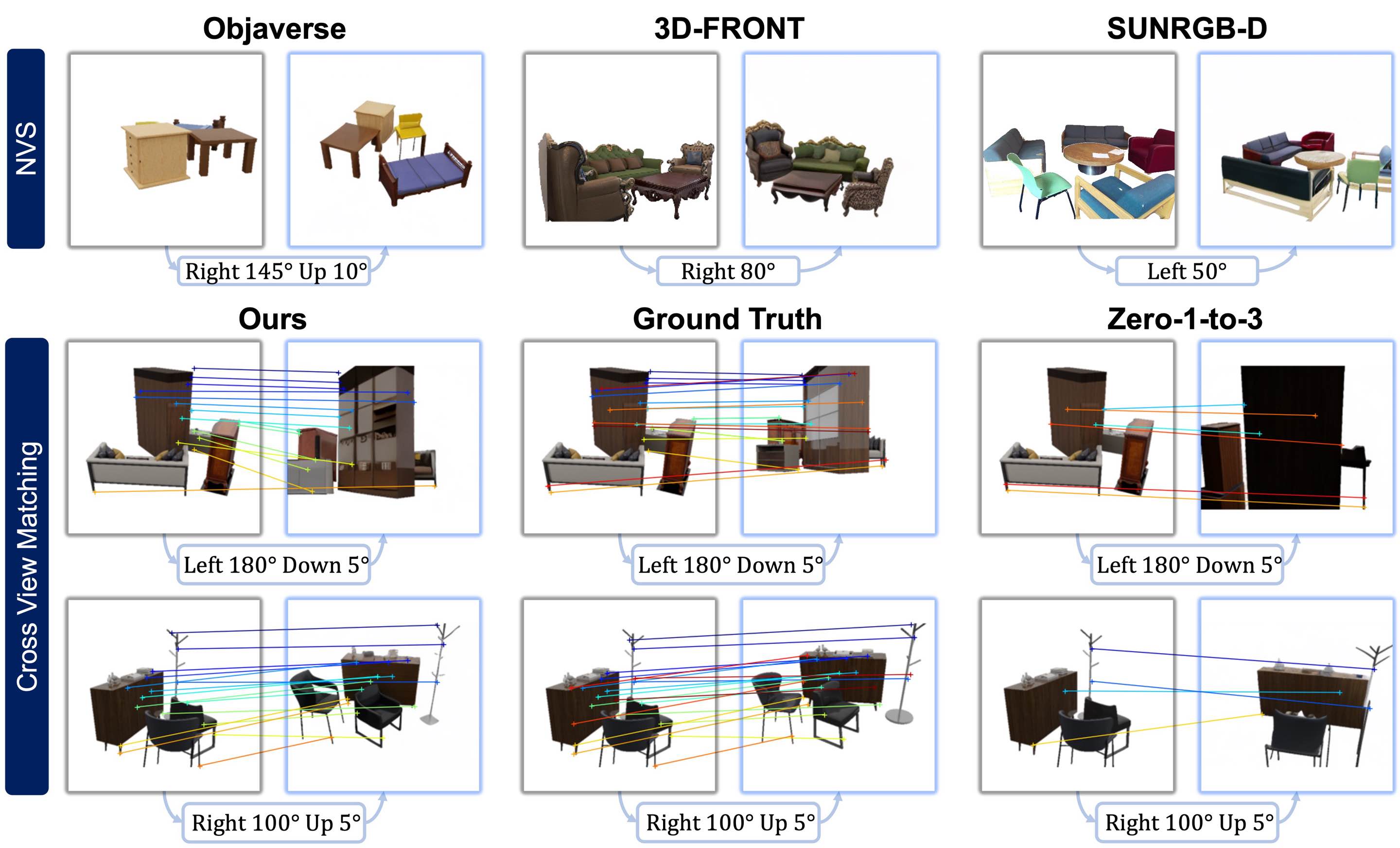
Ruijie Lu*, Yixin Chen*, Junfeng Ni, Baoxiong Jia, Yu Liu, Diwen Wan, Gang Zeng, Siyuan Huang CVPR 2025 [Paper] [Code] [Data] [Project Page] |
|
Yu Liu*, Baoxiong Jia*, Yixin Chen, Siyuan Huang ECCV 2024 [Paper] [Project Page] [Code] |

|
Baoxiong Jia*, Yu Liu*, Siyuan Huang ICLR 2023 [Paper] [Project Page] [Code] |
|
|
 |
Tsinghua University, China
2024.08 - now Ph.D. Student Advisor: Prof. Song-Chun Zhu |
|
Tsinghua University, China
2020.08 - 2024.07 Undergraduate Student Advisor: Prof. Song-Chun Zhu |
 |
Beijing Institute for General Artificial Intelligence(BIGAI), China
2021.09 - now Research Intern Advisor: Dr. Baoxiong Jia and Dr. Siyuan Huang |
|
|
|
Thanks for your visiting by 😊.
|